Search in SharePoint 2013
The first and foremost change to
search in SharePoint 2013 is there is only one search engine.
The idea that you use the FAST
engine for content and the SharePoint engine for people has been completely
eliminated. In SharePoint 2013 there is a brand new search core that combines
the best qualities and functionality of both SharePoint search and FAST search.
The powerful indexing, linguistics, extraction, and query expressiveness are
now evident throughout the platform. With this change comes another dramatic change
in overall search architecture. There is now only one query language across all
of SharePoint 2013, which combines the best features of FQL (FAST Query
Language), and KQL (Keyword Query
Language).

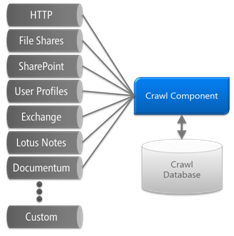

This adds a component to the
crawling feature to support anonymous crawling. Prior to this change, all
crawls needed to be associated to a user account or leverage other methods of
authentication.
Continuous
crawl
In SharePoint Server 2013, you
can configure crawl schedules for SharePoint content sources so that crawls are
performed continuously. Setting this option eliminates the need to schedule
incremental crawls and automatically starts crawls as necessary to keep the
search index fresh. Administrators should still configure full crawls as
necessary.
In SP2010, we have two types of
crawls; Full or Incremental Crawl. One of the limitations of Full and
Incremental Crawls in SP2010 is that they cannot run in parallel, i.e. if a
full or incremental crawl is in progress, the admin cannot kick-off another
crawl on that content source. This forces a first-in-first-out approach to how
items are indexed.
Moreover, some types of changes
result in extended run times; such as script based permission changes, or moving
a folder, or changing fields in a content type. Incremental crawls don’t remove
“deletes”, so ghost documents are still returned as hits, after deletion, until
the next full crawl.
SharePoint 2013 will introduce
the concept of “Continuous Crawl”. It doesn’t need scheduling. The underlying
architecture is designed to ensure consistent freshness by running in parallel.
Right now, if a Full or Incremental crawl is slow, everything else awaits its
completion. It’s a sequential crawl. Behind the scenes, continuous crawl
selection results in the kick-off of a crawl every 15minutes (this wait can be
configured) regardless of whether the prior session has completed or not. This
means a change that is made immediately after a deep and wide-ranging change
doesn’t need to ‘wait’ behind it. New changes will continue to be processed in
parallel as a deep policy change is being worked on by another continuous crawl
session.
Host
distribution rules removed
In SharePoint Server 2010, host
distribution rules are used to associate a host with a specific crawl database.
Because of changes in the search system architecture, SharePoint Server 2013 does
not use host distribution rules. Instead, Search service application
administrators can determine whether the crawl database should be rebalanced by
monitoring the Databases view in the crawl log.
Removing
items from the search index
In SharePoint Server 2010, Search
service application administrators could remove items from the search index by
using Search Result Removal. In SharePoint Server 2013, you can remove items
from the search index only by using the crawl logs.


Visual
metadata extraction
Support for extraction of
metadata using high-performance format handlers that allow for extraction of
titles, authors and dates from hTML, DOcX, PPTX, TXT, Image, XML, and PDF
formats. These format handlers look at font type and size, text alignment,
capitalization, and other visual cues that
we ourselves will generally use
to determine the title and author of a document.
Company
names entity extraction
First introduced in SharePoint
2010, company name entity extraction has undergone a serious facelift. Instead
of extraction dictionaries being managed in XML files on the file system like
in 2010, SharePoint 2013 now managed inclusion and exclusion dictionaries from
within the term store of the Managed Metadata Service. This greatly simplifies
the management and extension of this capability.
Result
Sources
Formerly known as scopes in
SharePoint 2010, the result sources tool in SharePoint 2013 now combines the
2010 concepts of scopes and federation into a new, powerful tool.
One of the most significant
features within result sources is the support for remote SharePoint index
federation. While simple on the
surface, this functionality fills a serious gap that existed in the overall
scalability of SharePoint 2010. FAST and SharePoint were criticized in the
marketplace for not having a global systems architecture. The approach was to
tell users to centrally index all content in a large central farm, if the
latency allowed.
Remote SharePoint indexing
addresses this problem by allowing federation with interleaving between local
and remote SharePoint indices. This gives SharePoint 2013 a true global architecture
solution that can be redundantly meshed to provide a scalable, fault tolerant
architecture.


Used in both feeding and query
processes:
Query: receives queries from the query processing component and provides results sets in return
It also physically moves around indexed content when the index architecture is changed by the Search Administration Component



FAST architecture is gone, but behind
the screens, Columns are now referred to as "partitions" and rows are
referred to as "replicas"
"Index partitions" and
"index replicas" have the same conceptual behaviors as rows and
columns. "Index partitions" allow you to index more content;
"Index replicas" allow you to provide redundancy for your queries
6. Query Processing Component

·
Performs linguistic processing at query time
·
Word breaking, stemming, query spellchecking,
thesaurus
·
Analyzes and processes search queries and
results.
·
When the component receives a query from the
search front-end, it analyzes and processes the query to attempt to optimize
precision, recall and relevancy. The processed query is then submitted to the
index component(s).
·
As part of this it also decides which query rules
are applicable, which index to send the query to, and whether to do any pre- or
post-processing of the query

Thumbnail Preview in FAST Search for SP 2010
In
SharePoint 2013:
·
The new Office Web Apps is the engine for
thumbnail previews in SharePoint 2013
·
The BIG WIN HERE – you can now browse through
the entire document in the preview
·
See all pages, see animations, zoom in, scroll
through the entire document
·
The point of this is to allow users to find the
exact item they’re looking for right in search results – no more clicking a result,
hitting the back button, and on and on until they find the one they’re looking
for
·
It also addresses the two major shortcomings of
thumbnails in SharePoint 2010:
·
It could only be used with FAST Search
·
It did NOT work with claims authentication
·
Since there’s only one search engine in
SharePoint 2013 you get document previews out of the box
·
In a different twist, previews only work with
claims authentication – it will not work with classic Windows authentication
Please refer below links to know
more about these types of authentication.
Search results will popup a
"preview" window which includes an Office Web Apps document preview,
but also includes some social media links, like "follow" the author
of this document.
8. Query Suggestions
It improves on the experience in
SharePoint 2010 as follows:
·
Your personal SharePoint activity factors into
the query suggestions, i.e. you have a personal query log
·
It includes weighting based on sites that you
have previously visited
·
It uses the most frequent queries across all
users that “match” the search terms
·
The behavior of the query suggestions turns into
more of a “browse and find” kind of experience
·
You can also add inclusion and exclusion lists
for suggestions via the SSA admin pages
·
When entering a query you will see two types of
suggestions:
·
A list of items you have clicked on before from
your personal query log
·
A list of items that others are typing for their
queries
·
When you get query results back, you will get
another set of suggestions
·
They are a list of links that you have clicked
through at least twice before and match your search criteria

There are two different modes for
the refiner web part: search results and faceted navigation.
·
With search results the refinement data works
essentially the same as SharePoint 2010
·
With faceted navigation it uses a term from the
term store to filter what kind of data should be displayed.
·
Refinement is different with SharePoint SharePoint
2013 in that you can define display templates to use for rendering different
kinds of refinements.In SharePoint 2010 you had to write your own custom refiner.
·
With Faceted Navigation, it is used in
conjunction with term sets that are used for navigation
·
With each term you select which managed
properties should be used as refiners with that term
·
Within the managed property you need to
configure it as “Refinable”
·
Example:
·
You have term store terms Camera and Laptop
·
You have managed properties Megapixel Count,
Color and Manufacturer
·
For Camera term, you add refiners for Megapixel
Count and Manufacturer
·
For Laptop term you add refiners for Color and
Manufacturer
The following section provides
details about the deprecated features in FAST Search Server 2010 for
SharePoint.
FAST Search
database connector
Description: The FAST
Search database connector is not supported in SharePoint 2013.
Reason for
change: The connector framework for SharePoint 2013 is combined with the
BCS framework and the Business Data Catalog connectors.
Migration
path: Replace the
FAST Search database connector with the Business Data Catalog-based indexing
connectors in the BCS framework.
FAST Search
Lotus Notes connector
Description: The FAST
Search Lotus Notes connector is not supported in SharePoint 2013.
The Lotus Notes indexing
connector (BCS framework) provides similar functionality as the FAST Search
Lotus Notes connector. The FAST Search Lotus Notes connector supports the Lotus
Notes security model. This includes Lotus Notes roles, and lets you crawl Lotus
Notes databases as attachments.
Reason for
change: The connector framework for SharePoint 2013 is combined with the
BCS framework and the Business Data Catalog connectors.
Migration
path: Replace the
FAST Search Lotus Notes connector with the Lotus Notes indexing connector, or
with a third-party connector.
FAST Search
web crawler
Description: The FAST
Search web crawler is not supported in SharePoint 2013.The SharePoint 2013
crawler provides similar functionality to the FAST Search web crawler
Reason for
change: The crawler capabilities are merged into one crawler
implementation for consistency and ease of use.
Migration
path: Use the
standard SharePoint 2013 crawler. The following table explains the differences
between the FAST Search web crawler and the SharePoint 2013 Preview crawler,
and provides details about migration.
Find similar
results
Description: The Find
similar results feature is not available in SharePoint 2013. The Find similar
results feature is supported in FAST Search Server 2010 for SharePoint to
search for results that resemble results that you have already retrieved.
Reason for
change: The Find similar results feature is available only within the
query integration interfaces, and it does not consistently provide good results
in many scenarios.
Migration
path: There is no
migration path available.
Anti-phrasing
Description: The search
anti-phrasing feature in FAST Search Server 2010 for SharePoint is not
supported in SharePoint 2013.
Anti-phrasing removes phrases
that do not have to be indexed from queries, such as “who is”, “what is”, or
“how do I”. These anti-phrases are listed in a static dictionary that the user
cannot edit.
In SharePoint 2013, such phrases
are not removed from the query. Instead, all query terms are evaluated when you
search the index.
Reason for
change: The FAST Search Server 2010 for SharePoint feature has limited
usage due to the limited number of customization options.
Migration
path: None.
Substring
search
Description: The
substring search feature was removed in SharePoint 2013.
In FAST Search Server 2010 for
SharePoint, substring search (N-gram indexing) can be used in addition to the
statistical tokenizer in East Asian languages. Substring search can be useful
for cases in which the normal tokenization is ambiguous, such as for product
names and other concepts that are not part of the statistical tokenizer.
Reason for
change: The feature has limited usage, and has very extensive hard disk
requirements for the index.
Migration
path: None
Number of
custom entity extractors
Description: In
SharePoint 2013, the number of custom entity extractors that you can define is
limited to 12.
In FAST Search Server 2010 for
SharePoint Service Pack 1 (SP1), you can define an unlimited number of custom
extractors. You can use custom entity extractors to populate refiners on the
search result page.
There are 12 predefined custom
entity extractors in SharePoint 2013:
·
Five whole-word case-insensitive extractors
·
Five word-part case-insensitive extractors
·
One whole-word case-sensitive extractor
·
One word-part case-sensitive extractor
Reason for
change: By using a predefined set of custom entity extractors, the
content processing architecture is more simple and easier to use.
Migration path: Use the
predefined set of custom entity extractors.
Supported
document formats
Description: SharePoint
2013 no longer supports rarely used and older document formats that are
supported in FAST Search Server 2010 for SharePoint by enabling the Advanced
Filter Pack. Both the ULS logs and the crawl log indicate the items that were
not crawled.
In SharePoint 2013, the set of
supported formats that are enabled by default is extended, and the quality of
document parsing for these formats has improved.
Reason for
change: The file formats for indexing are older formats and are no longer
supported.
Migration path: You can work with
partners to create IFilter-based versions of the file formats that can no
longer be indexed.
Custom XML
item processing
Description: FAST Search
Server 2010 for SharePoint includes a custom XML item processing feature as part
of the content processing pipeline. Custom XML item processing is not supported
in SharePoint 2013.
Reason for change: In SharePoint
2013, the content processing architecture has changed. Custom XML item
processing was removed and we recommend that you implement a mapping
functionality outside SharePoint.
Migration
path: Custom XML
item processing can be performed outside the content processing pipeline, for
example by mapping XML content to a SharePoint list, or to a database table
·
Office Web Apps is no longer a service
application
·
Seperated to own product
·
Web Analytics is no longer service application
·
Analyses and reporting process incorporated to
search service application
·
Overall SharePoint 2013 requires more resources
than 2010
·
SharePoint crawler will support
"anonymous" authentication for crawling website
·
Creating crawled and managed properties still
require a FULL crawl
No comments:
Post a Comment